
Hi all!
I hope that you are doing well. In this journal, I will explain the backup and restore strategy for Kubernetes using Velero, specifically in Google Kubernetes Engine (GKE).
As you may know, Velero is one of the great open-source tools which can be used to back up and restore (including migrate and replicate) our existing Kubernetes cluster. It has lots of features which we can use. First, absolutely it is open source. We can use Velero in all most Kubernetes environments. For example, on-premise, Google Kubernetes (GKE), or other public clouds. So, if you are already using Velero in another environment, you will easily adapt to it in GKE.
Based on the main documentation here, there are many use cases that we can use to implement using Velero, for example, backup filtering. Velero is also easy to use. We just have to install the binary and a bit of configuration to connect to the cluster, and it is ready to do backup and restore.
But, in this case, there are many limitations on Velero too. First, Velero does not natively support the migration of persistent volumes snapshots across cloud providers. If we want to do it, we need to enable Restic. Velero also does not support do restore into a cluster with a lower Kubernetes version than where the backup was taken. So, we need to ensure the version is properly and carefully.
Maybe, in previous experience, you’ve already tried Velero to execute backup and restore on-premise Kubernetes environment. This is the most common use case, but storage is one of the benefits of using the public cloud. We don’t necessarily to taking care of the backup storage because (for example, in GCP, we are using cloud storage) it is fully managed.
We just have to create a backup (if we don’t have one) that is ready to use.

Because Velero needs access the resources and the storage, we need to create a service account and define the permission. The permission must be attached to the service account is get, create, and delete. So the resources are accessible from Velero.


After the permission is configured, we now have to download the Velero. There are many architectures provided, and we can just choose it right away

And install it. Don’t forget to use GCP as the plugin and define the secret file to the secret file created earlier before. This is important, so the Velero can connect to the bucket

Okay. Now Velero is ready to use.
In this journal, for example, below is my GKE cluster. I am using Kubernetes with the version 1.22.12, and it has three workers nodes.

And there, I already deployed a wordpress application that uses PVC for storage and services with LoadBalancer type. You can follow along here.

There are many ways to do a backup. We can backup based on the namespace, on the label, and even the entire cluster, including cluster state. This depends on the use case. For example, I only want to do backup-specific namespace or deployment based on the label.
Here is the example if I only want to do a backup for wordpress namespace

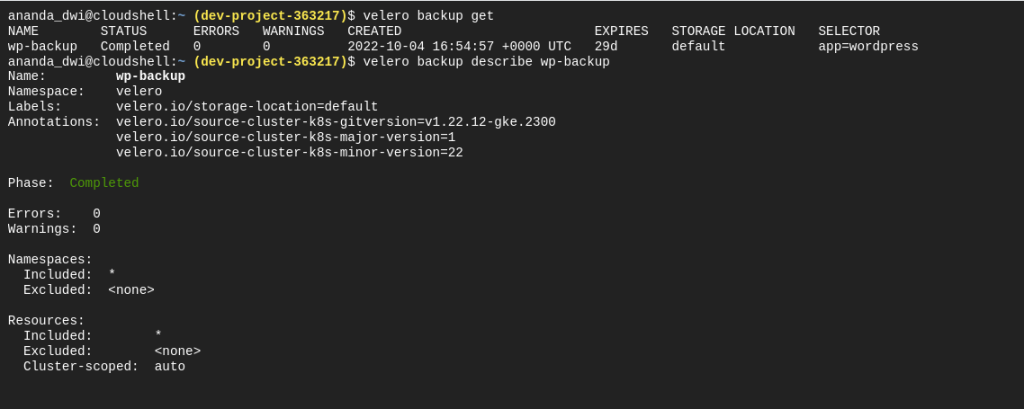
In another moment, we can do a backup automatically by scheduling it as daily like below

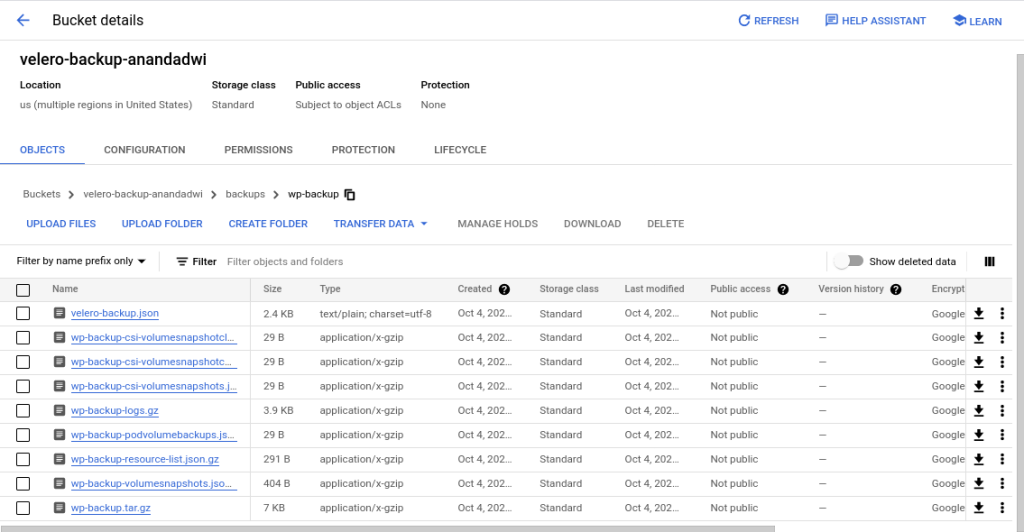
The resources will automatically back up into the storage defined before.
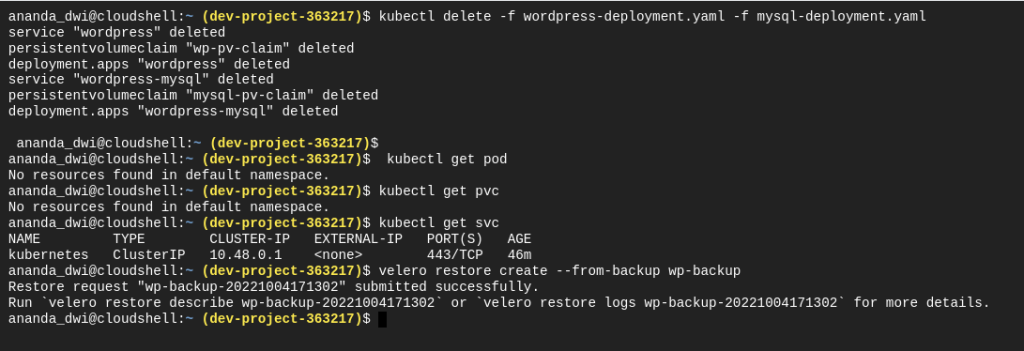
After backup is successful, how do restore it? For testing, we can delete the deployment first and try to restore it in the same cluster. Or if we have another cluster, we can restore it there too.
References:
- https://velero.io/docs/v1.9/
- https://gist.github.com/rcompos/adc4f0dd00e37df023fd78c5db7965ef
- https://github.com/vmware-tanzu/velero-plugin-for-gcp
Cheers!
